MDACA Data Flow (DF) provides a powerful enterprise-grade platform with capabilities to collect, route, enrich, transform and process data in a reliable and scalable manner. DF automates the movement of data between disparate data sources and systems, making data ingestion fast, easy and secure. DF provides real time and batch data ingestion data transfer between different sources and destination.
MDACA Data Flow (DF) provides real-time control to easily manage the movement of data between any source and any destination. The web-based user interface provides a seamless experience between design, control, feedback, and monitoring. It is extendable to support disparate and distributed data sources of differing formats, schemas, protocols, speeds and sizes such as machines, geolocation devices, click streams, files, social feeds, log files, videos and more. It supports the automation and movement of data, making data ingestion fast, easy and secure with nearly 300 out-of-the-box processors.
")
MDACA DF is based on the industry leading Apache NiFi with enhanced features and security configurations. DF has been upgraded to support enterprises with advanced DoD-grade security features, additional connectors, functions, and performance optimizations. Our DF Amazon Machine Image (AMI) includes Keycloak as part of the baseline configuration, supporting advanced enterprise security and master data management needs; this supports enterprise single-sign-on and user federation, strong authentication, user management, fine-grained authorization, and more.
Enterprise Grade, Leveraging Industry Standards
Government and commercial entities challenged with requirements to obtain data from multiple sources like legacy systems, databases, ERP, CRM, files, HTTP links, IoT data, etc. into an enterprise data repositories can leverage MDACA Data Flow to maximize the value of their data.

MDACA DF is designed for ingesting data from various sources supporting multi-cloud, hybrid-cloud and edge data collection. It provides industry leading, easy to use, well-rounded, scalable, fault tolerant solutions to handle entire “data flow” logistics of an enterprise. MDACA Data flow provides a single platform, supporting ~300 different sources and having the ability for batch ingestion and streaming ingestion into the platform.
In summary MDACA Data Flow is a comprehensive platform designed for:
- Data acquisition, transportation, and guaranteed data delivery
- Data-based event processing with buffering and prioritized queuing
- Accommodating highly complex and diverse data flows
- Providing a user-friendly visual interface for development, configuration, and control
Ingest Data From Any Source To Any Destination
In any Big Data project, the biggest challenge is to bring different types of data from different sources to support the enterprise interconnected data needs. DF is capable of ingesting any kind of data from any source to any destination. DF comes with nearly 300 in-built processors capable to transport data between systems. Additionally it is fully customizable to meet custom connectivity needs.

DF is a highly extendable / automated framework used for gathering, transporting, maintaining and aggregating data of various types from various sources to target destinations in a data flow pipeline. Additionally designed to support advanced Master Data Management needs, and is not limited to data ingestion only. DF can also perform data provenance, data cleaning, schema evolution, data aggregation, transformation, scheduling jobs and many others.
Key Features
Designed to provide a single view of enterprise data while concealing the technical complexities of database types, data locations, and data transformations, making it easy for business owners to understand.
User Friendly UI
Easy to use Web UI, providing the tools to design, control, and monitor flow execution
Real-time Data Flow
Real-time control to help manage the transfer of data between various sources and destinations
Scalable
Easily Scale out clusters in order to ensure data delivery
Highly Configurable
Easily configure directed graphs of data routing, transformation, and system mediation logic
Extendibility
Extendable framework facilitating the building of custom processors supporting agile and rapid development and effective testing
Automation
Automate the flow of data within a convenient drag and drop, configurable user experience
Master Data Management
Enforce data provenance, data quality, data cleansing and additional rules where data governance, history and accuracy is of the utmost importance
Security
Advanced integration with enterprise user management with support for SSL, SSH, HTTPS, encrypted content with advance authorization and policy management
DF Integration with Keycloak
MDACA DF is designed to work with Keycloak and other identity management providers to provide user federation, strong authentication, user management, fine-grained authorization, and more.

Securing the Digital Infrastructure
DF combined with Keycloak enables:
- Single Sign On (SSO) to login once for access to multiple applications
- Integrate with identity management providers and connect to existing user directories
- Support standard protocols such as OpenID Connect, OAuth 2.0, and SAML 2.0
- Centralized Management for administrators and users
DF Quick Start Program
We understand organization needs will differ based on business needs, budgets, interconnected partners, and ramp up timelines and requirements. The Quick Start Program is designed in collaboration with our industry partners to provide the agile approach to support the quick secure establishment of the baseline approach to meet your data access needs and support the onboarding and training of your teams.
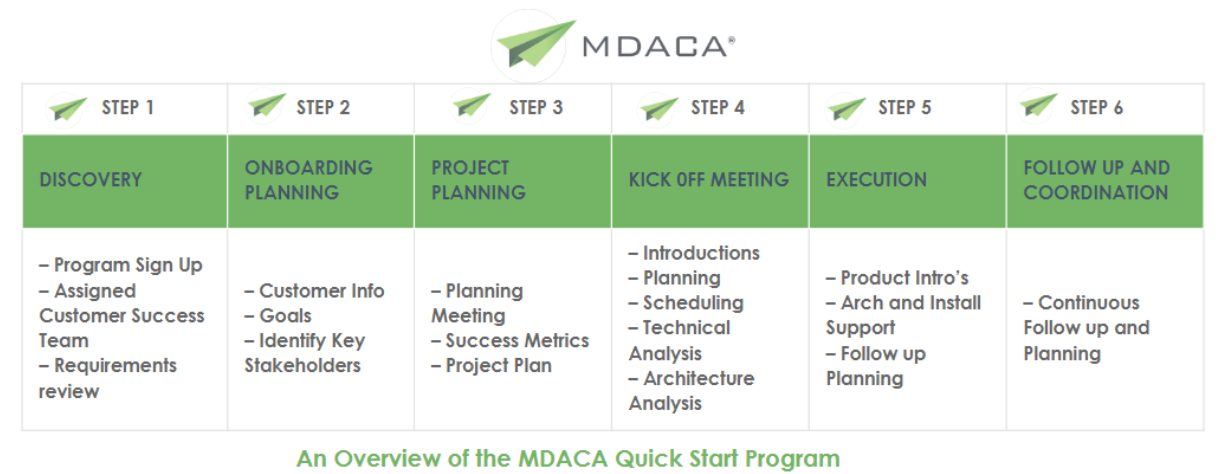
Additionally it is designed to provide your team’s direct access to our product and integration teams as part of the MDACA customer experience.
Training and Support
Our training and support program can be tailored to meet your needs. In addition to our staff that specialize in big data solutions, we have direct access to our industry partnerships that provide us access to a wide pool of resources that can tailor training specifically to your business and team’s needs. We offer a number of options in support of your training needs.

Certifications
